












Ça m'a pris environ 8h puisque je n'ai jamais touché à Python de ma vie, et je crois bien que je déteste ce langage maintenant ! Je me suis inspiré de plusieurs tutoriels que j'ai pu trouver sur Google et sur YouTube, et le résultat est plutôt concluant, mais j'ai bien galéré à faire fonctionner tout ça correctement..
-
Quelques indications :
- Déjà, le charset, va savoir pourquoi mais en UTF-8 ça ne m'affichait pas ce que je souhaitais, chez moi, la méthode qui a fonctionné, c'est de passer ça en ISO-8859-1 (pour avoir les accents ET les smileys).
- Ensuite, côté librairies pip et tout et tout, je n'ai pas pensé à noter tout ça, donc j'espère que tu t'y connais suffisamment pour installer ce qu'il te manque !
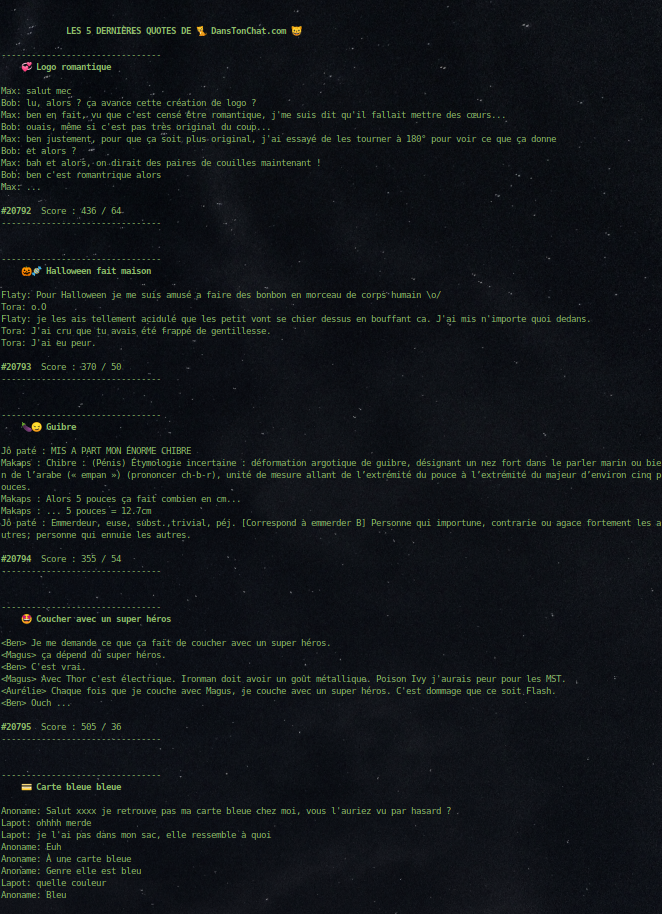
- Les quotes s'affichent par ordre décroissant, la plus récente est tout en bas, pour passer en croissant il faut modifier range(4, -1, -1) en range(5)
J'ai donc mis ça dans un fichier que j'ai nommé dtc.py comme on peut le voir ci-dessous.
Je l'exécute simplement avec la commande python3 !
Créé le 13/11/2020
Corrigé le 26/02/2023
Depuis le 26 Septembre, DTC a été migré sur WordPress, je n'ai pas eu le courage d'éditer le script donc ça ne fonctionne plus pour le moment ! N'hésitez pas à m'envoyer vos contributions.
Download @ GitHub
>>> python3 dtc.py
# coding: iso-8859-1 #!/usr/bin/env python3 from __future__ import unicode_literals import requests from bs4 import BeautifulSoup import sys from unidecode import unidecode import time import os import re while True: url = 'http://www.danstonchat.com' response = requests.get(url) if response.ok: os.system('clear') bashfr = '\n\n \033[1mLES 5 DERNIÈRES QUOTES DE 🐈 DansTonChat.com 😺\033[0m\n\n' sys.stdout.buffer.write(bashfr.encode('iso-8859-1')) codehtml = BeautifulSoup(response.text, 'lxml') for loop in range(4, -1, -1): divquotesgeneral = codehtml.findAll('div', {'class': re.compile('^item item')})[loop] titles = divquotesgeneral.find('h3') score = divquotesgeneral.find('span', {'class': 'score'}) quotenumber = divquotesgeneral['class'][1].replace('item', '#') print('\n--------------------------------'); sys.stdout.buffer.write(b' \033[1m' + titles.text.encode('iso-8859-1') + b'\n\n\033[0m') try: quotesimg = divquotesgeneral.find('a', {'class': 'html img', 'title': True}) if quotesimg: txt = quotesimg['title'].replace('<br />', ' ') sys.stdout.buffer.write(txt.encode('iso-8859-1')) else: quotes = divquotesgeneral.find('div', {'class': 'item-content'}) sys.stdout.buffer.write(quotes.text.encode('iso-8859-1')) except: print('Aucune quote ou site web inaccessible') print('\n\n\033[1m' + quotenumber + '\033[0m ' + score.text + '\n--------------------------------\n\n') time.sleep(3600)
Aperçu sur mon shell :